Posted 14 August 2024, 9:01 am EST - Updated 14 August 2024, 9:06 am EST
For several .PDF documents, I am able to use an export filter to export .PDFs to .html and then parse the .html for text.
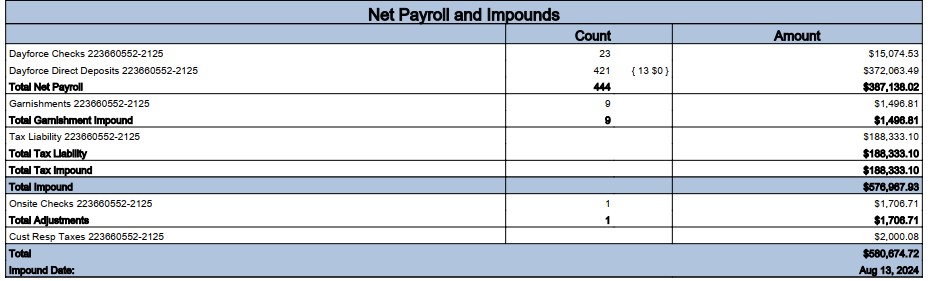
I have this one .PDF where the .html file is split such that each individual character is in it’s own html element, so I am unable to parse the .html efficiently.
The .PDF file has text, but when I use the Xls and Rtf export filters, the content is exported as an image.
Is there any sample that shows how to extract or iterate over the text fields in a .PDF?
I have the WinForms ComponentOne v4.0.20173.282 and a later version on my development machines.
Thanks for any advice or help in advance…
John
PDF file has a bunch of tables in it like below…