How to Extract Text from HTML Emails using ComponentOne Text Parser
The ComponentOne Text Parser is a .NET Standard library that can be used to extract fields from HTML. It can do other text parsing tricks, but for this article I’m going to focus on the task of extracting data from a common type of HTML file, an email.
Extracting data fields from HTML is a useful task in computing since many companies now deliver paperless invoicing. These emails contain relevant financial information that needs to be recorded, or maybe the marketing department needs to track lead emails that come from a web form.
These types of emails tend to follow a predictable structure which makes it possible for a program to parse with some degree of certainty. Through an email parser individual pieces of information such as item details, vendor info, shipping info, item costs, shipping costs, taxes, and total purchase cost can be extracted and recorded as fields which can then be recorded, or analyzed, or whatever.
Extracting Fields from HTML Emails using a Text Parser:
Step 1: Get ComponentOne Text Parser
There are a lot of text parsing tutorials and libraries out there. The ComponentOne Text Parser (C1TextParser) is a .NET Standard Library, which means that it can be integrated into practically any type of app or service you’re developing in Visual Studio.
The quickest and simplest way to get C1TextParser is through Nuget.
C1TextParser can also be downloaded and installed through the service components tile in the ComponentOne Control Panel (download from here). Downloading from this installer also gives you access to samples and other components.
Step 2: Create an Email Template
In most programmatic text extraction scenarios, we intend to repeat the process over and over. In this case, we want to go through a batch of emails and extract the relevant data from all of them. First, we need to define the template.
C1TextParser supports multiple types of extractors. One of them is an XML template-based extractor. But when working with HTML it’s best to use the specialized HTML Extractor.
It also uses a templated approach, but it’s special in a few ways:
- It’s flexible enough that if a new email does not follow the exact same html structure as the template, but there is still a high degree of similarity, the desired data can still be extracted.
- The template can be declared in a friendly way with only the necessary information about the location of the data fields. Basically, the data needs to be at the same location in the node structure of the file but the character count does not matter.
The way you define the HTML template is by adding placeholders for each field that you wish to extract. For each placeholder, you must provide the XPath of the html element containing the desired data field text. An XPath is basically a string that describes an XML path using forward slashes to indicate nodes, or html elements.
For example, in this email we will create a template placeholder for the expected delivery date.
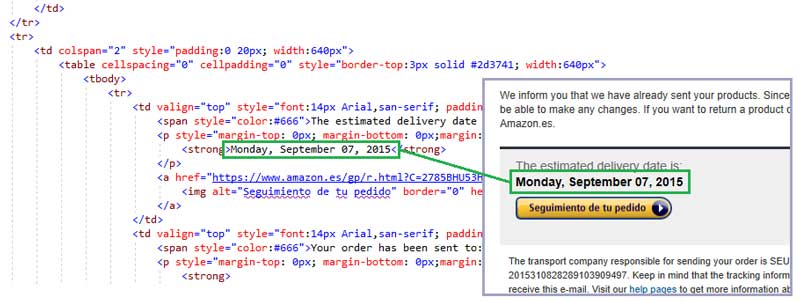
When we inspect the HTML, we can see this field is located within several DIV tags and within the 2nd row of a nested TABLE.
We create an XPath that looks like this:
//Fixed placeHolder for the expected delivery date
String deliveryDateXPath = @"/html/body/div[2]/div/div/div/table/tbody/tr[3]/td/table/tbody/tr[1]/td[1]/p/strong";
This XPath will get us whatever text is within the STRONG tag at that location.
Next, we can open the template file and create a placeholder using this XPath.
Stream amazonTemplateStream = File.Open(@"amazonEmail1.html", FileMode.Open);
HtmlExtractor amazonTemplate = new HtmlExtractor(amazonTemplateStream);
amazonTemplate.AddPlaceHolder("delivery date", deliveryDateXPath);
The placeholder name (“delivery date”) is what will be included in the output.
Repeat this process for each data field you want extracted and that completes the template.
Step 3: Extract, Extract, Extract
Building the template placeholders was the hard part. Extraction is the easy part! For each additional email, we can use the C1TextParser’s Extract method to initiate the full extraction.
// Extract an email following the template and output the result
Stream source = File.Open(@"amazonEmail1.html", FileMode.Open);
IExtractionResult extractedResult = amazonTemplate.Extract(source);
Console.WriteLine(extractedResult.ToJsonString());
Repeat this in your service, or app’s code however you need to. You may first want to scan a folder of files or download them from your inbox.
Step 4: Whatever
This is the whatever step, which means do whatever you need to do with the extracted data. You may need to store the data in a new file or database. In the code snippet above we just wrote the output to the console in Json format. C1TextParser can also output to a collection of objects.
If you download the C1TextParser samples, you’ll find that we show how to store the data in a CSV file in the ECommerceOrder sample.
Email Parser Web Demo
In step 2 we defined the template by typing out an XPath for each placeholder. That is tedious and prone to mistakes. One way to make it easier for both developers and end-users is to provide an interface that allows the user to select the data field text by clicking directly on the email.
Along with the text parser samples, we included a web app that does this by automatically generating the XPath placeholders for each field selected by the user. The sample is called EmailParserWebApp and it’s installed under your documents/ComponentOne Samples.
See and play with it live here: https://demos.componentone.com/TextParsers/EmailParserWebApp/home
Here’s a video that shows how the demo works:
Here are the steps to create a template using this demo:
- Select an email from the list to use as a template by clicking the “+Template” button.
- The template is created (you may rename it) and then the demo takes you to a page where you can start to select fields from within the email to generate placeholders.
- Select some text that represents a data field (the value only) and then click “Add Field”
- Name the field and repeat this process for each field.
- If there’s a repeated block, select the entire block and click “Add Repeated Block” and then repeat step 3 for each repeated field.
- Once you are done adding fields, click “Save Template” and the demo will take you back to the list of emails.
- Select the number of emails you’d like to parse using the selected template and click “Parse”.
- Finally, the demo shows the outputted JSON extracted from the list of emails.
The ComponentOne Text Parser can also do more generic text parsing using a standard template extractor, as well as a “starts-after-continues-until” extraction technique.
You can learn more about them from the Text Parser samples and documentation.
